
Introducing Dynex Quantum-Diffusion LLM (qdLLM): A Quantum-Enhanced Language Model
The rapid evolution of large language models (LLMs) has led to significant advances in natural language understanding and generation. However, classical diffusion-based language models still face challenges in coherence, logical consistency, and inference efficiency. Dynex is introducing a breakthrough solution: the Dynex Quantum-Diffusion Large Language Model (qdLLM). By integrating quantum computing into the token selection process of diffusion-based LLMs, qdLLM delivers a new level of performance, leveraging the power of quantum optimization to enhance language generation.

The Foundation: Diffusion-Based LLMs
Diffusion models originate from generative modeling techniques where structured data is progressively refined from an initial state of randomness. Unlike autoregressive models, which generate text sequentially one token at a time, diffusion-based LLMs work by iteratively denoising an initial sequence of masked or noisy tokens until a coherent response emerges.

The process follows these steps:
- Forward Diffusion (Noise Injection): A well-formed text sequence is progressively corrupted by replacing tokens with noise (e.g., masked tokens or Gaussian noise in an embedding space). This transforms meaningful text into a more randomized state.
- Reverse Diffusion (Denoising Process): The model learns to recover the original sequence by iteratively predicting which tokens to unmask at each step, using contextual information from the remaining tokens.
- Score-Based Token Selection: At each step, a scoring function evaluates possible token completions, guiding the denoising process toward plausible, high-quality outputs.

For example, Inception Labs’ diffusion large language models (dLLMs) introduce a novel approach to text generation by refining outputs from an initial noisy state to coherent text. This coarse-to-fine generation process enables parallel token generation, leading to significant improvements in speed and efficiency. Notably, dLLMs can generate tokens 5–10 times faster than traditional autoregressive models, achieving throughputs exceeding 1000 tokens per second on standard hardware. Additionally, this parallelism allows for more efficient GPU utilization, resulting in cost reductions of up to 10 times compared to conventional LLMs.
While diffusion models allow more flexibility in handling complex text dependencies, they introduce computational challenges in selecting the most relevant tokens at each step. This is where qdLLM leverages quantum computing to optimize token selection.
The Quantum Advantage in qdLLM
The key innovation of qdLLM is the use of quantum computing to optimize token selection at each diffusion step. Instead of relying solely on classical heuristics or stochastic approaches, Dynex’s quantum-enhanced method formulates token unmasking as a quantum algorithm task. By leveraging Dynex’s quantum platform, qdLLM efficiently identifies the most relevant token combinations for each step, significantly improving response quality.
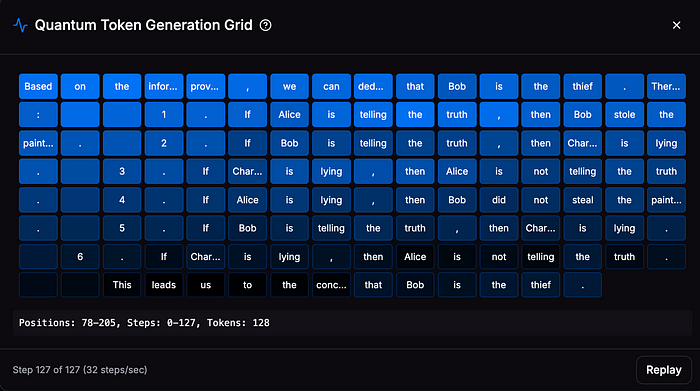
How qdLLM Works
The architecture of qdLLM consists of three main components:
- Core LLM for Token Prediction — This module predicts possible token completions based on context and previous diffusion steps, ensuring grammatical correctness and semantic coherence.
- Quantum Module for Token Selection — At each diffusion step, a quantum annealer selects the optimal tokens to unmask, solving a quantum algorithm problem that maximizes coherence, logical consistency, and contextual relevance.
- Hybrid Orchestration Layer — This layer manages the interplay between quantum and classical components. During early diffusion steps, quantum annealing determines foundational elements of the response. As confidence increases in later steps, the system transitions to classical methods for fine-tuned token selection and refinement.
Benefits of the Hybrid Quantum-Classical Approach
By combining quantum and classical methods, qdLLM achieves:
- Improved Coherence — The quantum-enhanced token selection process leads to more naturally flowing responses.
- Higher Logical Consistency — Quantum optimization ensures that critical elements of an answer are established early, reducing logical errors.
- Better Factual Accuracy — The structured diffusion process minimizes hallucinations and aligns responses with the intended context.
- Efficient Inference — By leveraging quantum computing in the early stages and classical refinement in later steps, qdLLM balances computational efficiency with response quality.
Unlocking the Future of Quantum Language Models
Dynex’s qdLLM is a major step toward practical quantum-enhanced AI, demonstrating how quantum computing can augment classical LLMs in meaningful ways. As quantum hardware and algorithms continue to evolve, the potential for further breakthroughs in natural language processing grows. By integrating quantum optimization into diffusion-based text generation, Dynex is paving the way for the next generation of AI-powered applications.
About Dynex
Dynex is a global leader in Quantum-as-a-Service (QaaS) technology, offering an affordable, accessible and scalable solution for quantum computing underpinned by a robust commitment to ethical integrity.
Dynex leverages neuromorphic quantum computing emulations with up to 1 million algorithmic qubits, to solve real-world problems at scale. Across academia and different industries from artificial intelligence, pharmaceuticals, finance, aerospace and more, Dynex drives exponential growth in the most complex fields, meeting the increasing demand for advanced computing solutions.
![Dynex [DNX]](https://miro.medium.com/v2/resize:fill:128:128/1*AbAXB_y5DEv8IrXdFkgdTw.png)